


Etiske principper for kunstig intelligens

SXSW 2019 møder regeringens nationale strategi for AI: En slags guide til (og løs diskussion af) etik, filosofi og de dilemmaer der følger med, når kunstig intelligens er under udvikling.
Jeg var en tur i Austin, Texas til SXSW 2019, hvor jeg fulgte en del talks og debatter om kunstig intelligens og tech ethics. Her blev der på livet løs diskuteret diversitet, forklarlighed, respekt, privatliv og andre centrale etiske begreber.
Og selvsamme uge som jeg kom hjem fra SXSW, udkom regeringens nationale strategi for kunstig intelligens, der bl.a. inkluderer seks etiske principper for kunstig intelligens.
Denne artikel er en gennemgang af regeringens seks etiske principper for kunstig intelligens set i lyset af de takeaways, jeg tog med hjem fra Austin.
Jeg beklager på forhånd: Der er tale om et lidt langhåret longread – grib hellere en god kop kaffe. God læsning :)
" 1. SELVBESTEMMELSE
Menneskets autonomi prioriteres i udvikling og anvendelse af kunstig intelligens. Mennesket skal som i dag kunne træffe oplyste og selvstændige valg, uden at kunstig intelligens fjerner menneskets selvbestemmelse.”
Autonomi er retten til selvbestemmelse. Det er tanken om, at man som individ bør have mulighed for selvforvaltning uden tvang eller indblanding.
En måde at forstå autonomi-begrebet er at se på det som et normativt krav om fravær af manipulation eller fremmedstyring. Her er spørgsmålet så, hvornår der er tale om manipulation i modsætning til ”oplyste og selvstændige valg”?
Vi færdes hver dag på Google og Facebook, som langt hen ad vejen er bygget op efter et ”don’t make me think”-design. Platformenes algoritmer sørger for, at relevant viden finder vej til min skærm. Det betyder, at det er store tech-giganter der i vid udstrækning bestemmer, hvad der er relevant for mig. Man kan kalde det manipulation. Man kan også kalde det en fortræffelig service. Men det eneste autonome valg den almindelige bruger har er, om han/hun vil bruge servicen eller ej.
Tænk også på selvkørende biler. Hele kongstanken bag selvkørende biler er, at de kan gøre det bedre end os. Statistisk set og på den lange bane er det meningen, de skal være bedre bilister end os, fordi de er bedre til at undgå dødsulykker end vores såkaldte autonome valg.
Det er et populært filosofisk synspunkt, at autonomi er forudsætningen for at foretage moralske valg. Her mener jeg ikke blot autonomi som et normativt krav, men autonomi forstået som en reel menneskelig egenskab, altså en fri vilje, som kan bryde årsagsvirkningskæder (fx psykologiske dispositioner, som formodentligt bygger på biokemi, som igen bygger på fysikkens love).
Lad os antage, at vi har en fri vilje, så er moralske valg (eller dilemmaer, som moralske valg typisk er) stadig notorisk vanskelige. Selv når man har tid og ro til at reflektere. Hvad med de splitsekund-valg som vi såkaldt autonome individer nogle gange må tage i trafikken?
Måske disse valg kan foretages bedre af en AI, som er trænet til at vælge det moralsk rigtige?
Det kan du hjælpe med at afgøre: The Moral Machine er et projekt på MIT, som indsamler menneskelige perspektiver på moralske beslutninger foretaget af maskin-intelligens.
Her er ét ud af en masse andre dilemmaer: En selvkørende bils bremser svigter og bilen kan vælge 1) at køre ind i kvindelig atlet og mandlig kriminel, eller 2) svinge ind i en betonklods og dermed dræbe de to passagerer, som i dette tilfælde er to hunde.
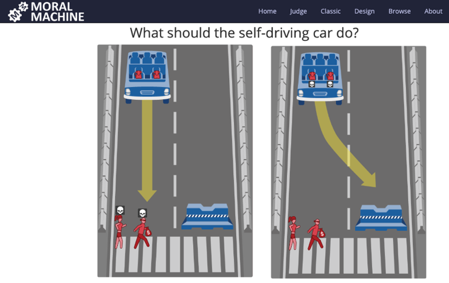
Der er tale om AI-relaterede varianter af såkaldte ”trolley problems”, som i moralfilosofiens verden er klassiske tankeeksperimenter designet til at teste nytteetiske versus pligtetiske intuitioner.
Test dine egne autonome valg her. Det er sjovt, men også ret seriøst: The Moral Machine.
" 2. VÆRDIGHED
Menneskets værdighed skal respekteres i udvikling og anvendelse af kunstig intelligens. Kunstig intelligens må ikke gøre skade på mennesker og skal understøtte retssikkerhed og ikke uberettiget stille personer dårligere. Kunstig intelligens skal respektere demokratiet og demokratiske processer, og det må ikke anvendes til at krænke menneskets grundlæggende rettigheder.”
Hørt! AI og digital teknologi med viralt potentiale forstærker både det gode og det dårlige i mennesker – og i samfundet som helhed. Vi har set fænomener som fake news, Cambridge Analytica, deep fakes, Putins troldehær etc. Men vi ser heldigvis også en spirende bevidsthed om digital dannelse.
På SXSW trak den fremadstormende demokrat fra Bronx Alexandria Ocasio-Cortez fulde huse. Hun sagde bl.a: “Don’t fear that the government takes over companies – fear that corporations have taken over our government.“ Og så slog hun et slag for at teknologisk automatisering også automatiserer uretfærdigheder.
Jeg oplevede hende ikke som teknologikritisk, men som kapitalismekritisk, forstået på den måde, at blot fordi du er god til at tjene penge, så er du ikke hinsides etisk forpligtelse. Hvilket jo på denne side af Atlanten ”i den gamle verden” er ret ukontroversielt.
Læs også: 6 temaer inden for kunstig intelligens lige nu (2019)
" 3. ANSVARLIGHED
Alle led skal være ansvarlige for konsekvenserne af deres udvikling og anvendelse af kunstig intelligens, dvs. blandt andet udviklere, samarbejdspartnere, anvendere, myndigheder og virksomheder. Det skal ved beslutninger og beslutningsunderstøttelse truffet af kunstig intelligens være muligt at stille mennesker til ansvar.”
Spørgsmålet er, om det er den enkelte udvikler og den enkelte bruger, der skal stå til ansvar? Det er det jo nok; for hvis vi accepterer, at individer altid har en etisk fordring, så gælder det jo også ift. teknologi – hermed også AI.
Vores egen konkurrencekommissær Margrethe Vestager var også på scenen på SXSW. Uden at tage politisk parti, så er jeg fanboy af hendes optræden. Hun citerede Spiderman: ”With great power comes great responsibility.” Hvis du er stor, så har du også et særligt ansvar. AI skal være menneskecentreret og skal skabe værdi for borgerne. Det er ikke borgerne (og deres data), der skal skabe værdi for tech-virksomhederne. Det er teknologien, der skal tjene os som borgere.
Teknologi er ikke i sig selv (etisk) godt eller skidt. Det handler om med hvilke formål, vi udvikler teknologien, og hvad vi konkret bruger den til.
Som Gerri Kasparov (den verdensberømte, russiske stormester i skak, som i 1996 tabte sit første parti skak til IBM-computeren Deep Blue) sagde til en talk på SXSW i år: “Technology is the reason why so many people are alive to benefit from the technology”.
Det var også teknologien der muliggjorde, at vi var 100.000 mennesker, der kunne mødes i Texas og diskutere teknologi. Det var selvfølelig også vores brug af teknologien, som efterlod et carbon footprint …
Når de helt store (fx Google, Amazon, Facebook, Apple og Microsoft) har et særligt ansvar, så er det fordi, de er en del af vores demokratiske infrastruktur: Viden og holdninger mødes og brydes på og med disse teknologier – men hvilket indhold, der når frem til vores respektive news feeds, styres bl.a. af Facebooks algoritmer.
Facebook benytter sig også af mennesker til at moderere indhold, hvilket har været udsat for kritik, til dels fordi moderatorernes job er psykologisk belastende, fordi jobbet består i at screene vold, voldtægt, halshugninger etc. Samtidig kritiseres Facebooks moderatorer for i deres screening ikke at være i stand til at skelne mellem fx hate speech og terror – og så politisk holdningskommunikation, som i andre henseender opfattes som inden for skiven af det juridisk og moralsk tilladelige.
AI kommer til at spille en større rolle i fremtiden ift. indholdsmoderation, men samtidig fordrer ansvarlighedsprincippet jo, at det skal være muligt at stille mennesker til ansvar. Det kan vi vælge at se som et paradoks – fordi AI på den ene side kan værne mennesker mod ubehageligt og skadeligt indhold, men på den anden side også begrænse menneskers ytringsmuligheder (hvilket jo parentes bemærket ikke er det samme som at knægte ytringsfriheden).
Men vi kan også se det som et underliggende forsigtighedsprincip eller et ”no harm principle”: AI kan hjælpe mennesker, hvis – og kun hvis – AI ikke skader mennesker. Eller som Google engang havde som uofficielt motto: ”Don’t be evil”.
Læs også: Små, men store: Er du opmærksom på styrken i mikrointeraktioner?
" 4. FORKLARLIGHED
Forklarlighed indebærer, at man kan beskrive, kontrollere og genskabe data, bagvedliggende logikker og konsekvenser af anvendelsen af kunstig intelligens, fx ved at kunne spore og forklare beslutninger og beslutningsunderstøttelse. Forklarlighed er ikke ensbetydende med fuld transparens omkring algoritmer, da der blandt andet er forretningsmæssige hensyn i den private sektor. Offentlige myndigheder har dog et særligt ansvar for at sikre åbenhed og gennemsigtighed ved brug af algoritmer.”
Forklarlighed (explainability) blev diskuteret heftigt i Texas. En af de helt store udfordringer med AI’s algoritmer er, at de for brugeren – også den professionelle bruger af forskellige systemer – er en ”black box”. På brugerniveau ved man, hvad der er input og hvad der er output, men man har ingen kontrol eller indsigt i, hvad der sker derimellem – eller hvorfor.
Kravet om forklarlighed betyder, at systemet selv skal kunne forklare, hvorfor systemet vælger, som det gør.
Tag fx et system, som afgør hvilke vilkår en låntager eller forsikringstager kan få. Algoritmen er trænet på baggrund af statistikker, der mange steder afgør, om man kan optage et lån eller hvad en forsikring skal koste.
Ifølge forklarlighedsprincippet skal systemet kunne blotlægge de bagvedliggende kriterier og statistikker. For er det rimeligt, at man betaler mere for sin forsikring, fordi man bor i et område med mange indbrud? ”Ja”, vil de fleste nok sige. Men er det også rimeligt, at man betaler mere for sin forsikring, hvis man fx har et arabisk navn? Det er der nok flere, der vil finde tvivlsomt.
Kravet om forklarlighed betyder, at man kan spørge ”hvorfor” til en computer – og dermed hjælpe med at blotlægge fx systemisk diskrimination (se punkt 5. om lighed og retfærdighed).
Ifølge ovenstående principformulering af forklarlighed stipuleres det, at ” Forklarlighed er ikke ensbetydende med fuld transparens omkring algoritmer, da der blandt andet er forretningsmæssige hensyn i den private sektor.” Det er vist det, der hedder en kattelem.
Forfatterne til strategien anerkender tilsyneladende, at forklarlighed er et centralt etisk begreb inden for kunstig intelligens, men går ikke linen uden. Spørgsmålet er, om det er en trækken i land som i realiteten stækker forklarlighedsprincippet? Eller er det bare en ukrænkelig ret at have forretningshemmeligheder?
En ide kunne jo være, at vi i fremtiden havde explainability audits, så virksomheders algoritmer kunne certificeres af uvildige instanser på samme måde som vi i dag har øko- og bæredygtighedscertificeringer. På den måde kan man måske få styr på etikken uden at kompromittere forretningen.
Et spøjst kuriosum ved forklarlighedsprincippet er, at det er et krav, vi aldrig ville stille mennesker. Menneskers intentioner, motivationer og grundlæggende overbevisninger er jo notorisk dunkle.
Hvorfor gjorde du som du gjorde i en given situation? Prøv at give svar på det – uden blot at isolere det til den givne situation. Din genetik, dine hormoner, din livshistorie, din dagsform etc. spiller ind. Tonsvis af komplekse forgreninger af årsagsvirkningsforløb (hvilket svarer til vores algoritmer) har en betydning – og ingen har en jordisk chance for at give det fulde svar.
Men derfor kan vi jo godt forlange det fulde svar af maskinerne. Der er ingen tvivl om, at forklarlighed vil blive et centralt debatemne, når vi vurderer de algoritmer, som i stigende grad kommer til at påvirke vores liv.
Læs også: Chatbots er ikke for alle – er det noget for jer?
" 5. LIGHED OG RETFÆRDIGHED
Kunstig intelligens må ikke reproducere fordomme, der marginaliserer befolkningsgrupper. Der skal arbejdes aktivt for at forhindre uønsket bias og fremme designs, der undgår kategorisering, som diskriminerer på baggrund af fx etnicitet, seksualitet og køn. Demografisk og faglig diversitet bør være en rettesnor i arbejdet med kunstig intelligens.”
IBM’s kloge og nærmest altvidende Watson er en mand, mens assistenter som Siri og Alexa er servile kvinder. Det er et eksempel på en kønsbias, som er nem at lave om på, fordi det jo formodentlig er et bevidst designvalg.
Et andet eksempel er teknologi til ansigtsgenkendelse. Både Apple og Amazon er blevet kritiseret for at være ringere til at genkende mørke kvinder end lyse mænd. Det skyldes, at mørke kvinder har været underrepræsenteret i den data, som AI’en er blevet trænet med.
Et andet eksempel på bias er software som politiet nogle steder i USA benytter til at forudsige sandsynligheden for, at tidligere dømte har høj eller lav risiko for at begå kriminalitet. Her bliver mørke personer nogle gange vurderet til at være ”high risk”, selvom de kun har begået småforbrydelser, mens hvide personer til sammenligning bliver vurderet som ”low risk”, til trods for, at de har begået grovere kriminalitet.
Årsagen skal findes i den træningsdata, som systemet benytter til at lære at lave forudsigelser. Argumentet er, at denne data allerede har en skævvridning, fordi den bygger på årevis af strukturel racisme, hvor politiet har forudsat at mørke personer begår mere kriminalitet og derfor har udøvet såkaldt ”racial profiling” – og dermed øget den statiske overrepræsentation af ikke-hvide. For træningsdata gælder det nemlig: Bias in – bias out.
Sætter man strøm til social uretfærdighed, så er den store fare at man med AI også forstærker social uretfærdighed.
Diversitetsdiskussion fyldte meget på SXSW 2019. Jeg hørte bl.a. talks med titler som ”Are there civil rights in a tech world?” og ”Ethics and responsibility in the AI and IoT age”, hvor diversitet blev tematiseret som et ansvar, man både har når man ansætter folk og bygger ny teknologi – fordi netop disse to aspekter er knyttet sammen. Hvis det kun er hvide college kids fra elite-universiteter, som ryger direkte til Silicon Valley, så er det deres tænkning, kulturelle perspektiver og biometri, som dominerer teknologiens design.
Det skal bemærkes at samme bias, blot med omvendt fortegn, gør sig gældende i Kina, hvor AI-teknologien buldrer frem. Her har de nærmest uanede datamængder, ingen privatlivslovgivning – men jo kun kinesisk data – og dermed en ansigtsgenkendelsesteknologi som er bedst til at genkende kinesere.
I Danmark er diversitetsdebatten til tider skinger og kørt af sporet, fordi der er opstået et falsk modsætningsforhold mellem retten til at føle sig krænket over hvad som helst, og retten til at sige og gøre hvad som helst – hvor ingen af disse yderpositioner jo nok rigtigt findes.
Princippet om lighed og retfærdighed handler om, at systemer ikke må reproducere marginaliserende fordomme. Og ikke om den enkeltes (stædige) ret til at bruge ord som andre finder stødende i visse kontekster. Derfor er princippet overordentligt relevant – og måske endda befordrende for at køre den lidt skæve diversitetsdiskussionen tilbage på sporet herhjemme.
" 6. UDVIKLING
Kunstig intelligens kan være med til at skabe store fremskridt for samfundet. Der bør skabes tekniske og organisatoriske løsninger, der understøtter etisk ansvarlig udvikling og anvendelse af kunstig intelligens for at opnå størst mulige fremskridt for samfundet fx ved at bidrage til bedre service fra det offentlige og vækst i erhvervslivet.”
Udvikling koster penge – men faktisk har regeringen lige smidt 30 millioner efter et udviklingsprojekt som er centralt for udviklingen af AI, nemlig den del der handler om natural language processing.
En sprogbank skal, som en del af regeringens nationale strategi for kunstig intelligens, fyldes med eksempler på korrekt dansk, så dansktalende kunstig intelligens får langt bedre træningsdata. De, der på brugerniveau har leget med Siri og Google Home Assistent (eller andre talende dimser), har nok konstateret, at deres dansk er lidt gebrokkent. Vi er simpelthen for lille et sprogområde til at globale spillere gider skabe tilstrækkeligt gode sprogdatabaser, som de talende maskiner kan bruge som træningsdata.
En sprogbank er ikke blot kulturpolitik anno 2019, det er formodentligt bydende nødvendigt for overhovedet at følge med. I 2020 forventes 20 % af verdens data at blive skabt i Kina og i 2030 er tallet 30 %. Data er forudsætningen for kunstig intelligens – så vi er bagud på point udelukkende på grund af vores størrelse.
Forhåbentlig kan vi være forud på etik. Det handler ikke om at være for eller imod den teknologiske udvikling. Vi kan ikke styre, at udviklingen sker, men vi kan demokratisk styre, hvad vi vil med udviklingen.
Du nåede til bunds! Hvis du har appetit på mere om AI og kunstig intelligens, så ser vi i artiklen 6 temaer inden for kunstig intelligens nærmere på, hvad kunstig intelligens kan bruges til.